publicSpringValueProcessor(){ this.placeholderHelper = new PlaceholderHelper(); }
@Override public Object postProcessBeforeInitialization(Object bean, String beanName)throws BeansException { Class clazz = bean.getClass(); for (Field field : findAllField(clazz)) { processField(bean, beanName, field); } for (Method method : findAllMethod(clazz)) { processMethod(bean, beanName, method); } return bean; }
private List<Field> findAllField(Class clazz){ final List<Field> res = new LinkedList<>(); ReflectionUtils.doWithFields(clazz, res::add); return res; }
private List<Method> findAllMethod(Class clazz){ final List<Method> res = new LinkedList<>(); ReflectionUtils.doWithMethods(clazz, res::add); return res; }
/** * 成员变量上添加 @Value 方式绑定的配置 * * @param bean * @param beanName * @param field */ protectedvoidprocessField(Object bean, String beanName, Field field){ // register @Value on field Value value = field.getAnnotation(Value.class); if (value == null) { return; } Set<String> keys = placeholderHelper.extractPlaceholderKeys(value.value());
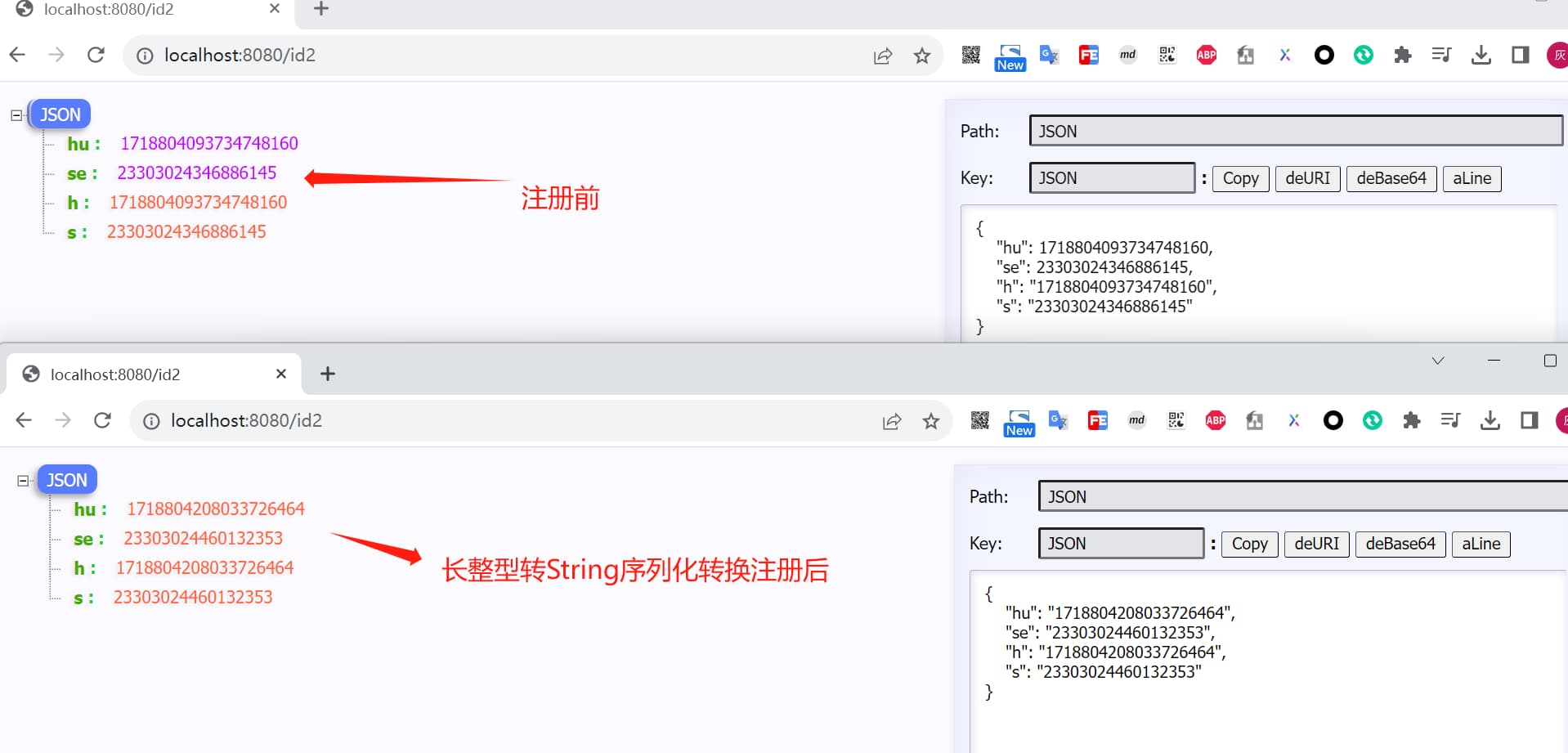
@ResponseBody @GetMapping(path = "id2") public IdVo id2(){ Long hu = huToolSnowFlakeProducer.nextId(); Long se = selfSnowflakeProducer.nextId(); returnnew IdVo(hu, se); }
privatevoidhandleErrorLoggingOnJacksonInitialization(Throwable e){ String warningMessage = "[THYMELEAF] Could not initialize Jackson-based serializer even if the Jackson library was detected to be present at the classpath. Please make sure you are adding the jackson-databind module to your classpath, and that version is >= 2.5.0. THYMELEAF INITIALIZATION WILL CONTINUE, but Jackson will not be used for JavaScript serialization."; if (logger.isDebugEnabled()) { logger.warn("[THYMELEAF] Could not initialize Jackson-based serializer even if the Jackson library was detected to be present at the classpath. Please make sure you are adding the jackson-databind module to your classpath, and that version is >= 2.5.0. THYMELEAF INITIALIZATION WILL CONTINUE, but Jackson will not be used for JavaScript serialization.", e); } else { logger.warn("[THYMELEAF] Could not initialize Jackson-based serializer even if the Jackson library was detected to be present at the classpath. Please make sure you are adding the jackson-databind module to your classpath, and that version is >= 2.5.0. THYMELEAF INITIALIZATION WILL CONTINUE, but Jackson will not be used for JavaScript serialization. Set the log to DEBUG to see a complete exception trace. Exception message is: " + e.getMessage()); }
public Date parse(String source, ParsePosition pos){ thrownew UnsupportedOperationException("JacksonThymeleafISO8601DateFormat should never be asked for a 'parse' operation"); }
public Object clone(){ JacksonThymeleafISO8601DateFormat other = (JacksonThymeleafISO8601DateFormat) super.clone(); other.dateFormat = (SimpleDateFormat) this.dateFormat.clone(); return other; } }
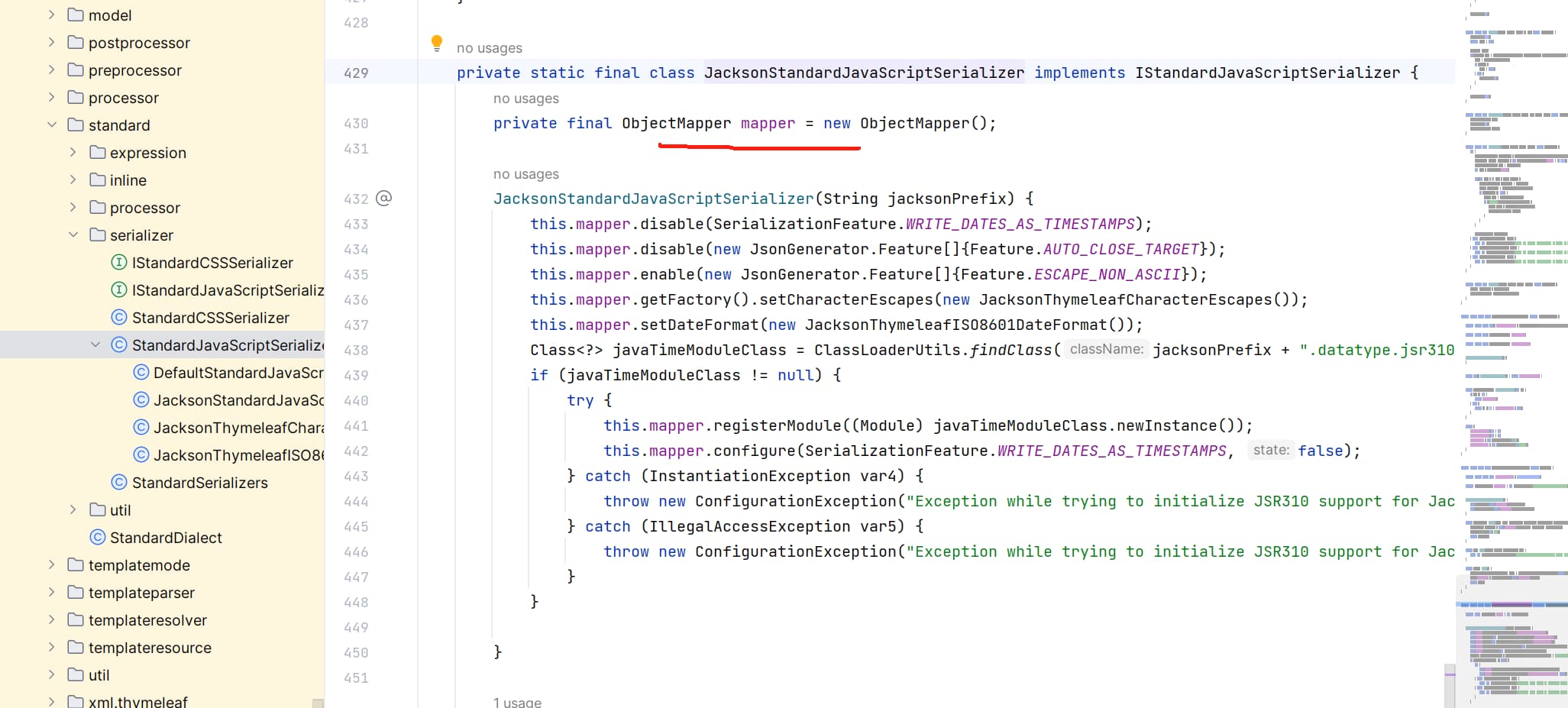
privatestaticfinalclassJacksonStandardJavaScriptSerializerimplementsIStandardJavaScriptSerializer{ privatefinal ObjectMapper mapper = new ObjectMapper();
JacksonStandardJavaScriptSerializer(String jacksonPrefix) { this.mapper.disable(SerializationFeature.WRITE_DATES_AS_TIMESTAMPS); this.mapper.disable(new JsonGenerator.Feature[]{Feature.AUTO_CLOSE_TARGET}); this.mapper.enable(new JsonGenerator.Feature[]{Feature.ESCAPE_NON_ASCII}); this.mapper.getFactory().setCharacterEscapes(new JacksonThymeleafCharacterEscapes()); this.mapper.setDateFormat(new JacksonThymeleafISO8601DateFormat()); Class<?> javaTimeModuleClass = ClassLoaderUtils.findClass(jacksonPrefix + ".datatype.jsr310.JavaTimeModule"); if (javaTimeModuleClass != null) { try { this.mapper.registerModule((Module) javaTimeModuleClass.newInstance()); this.mapper.configure(SerializationFeature.WRITE_DATES_AS_TIMESTAMPS, false); } catch (InstantiationException var4) { thrownew ConfigurationException("Exception while trying to initialize JSR310 support for Jackson", var4); } catch (IllegalAccessException var5) { thrownew ConfigurationException("Exception while trying to initialize JSR310 support for Jackson", var5); } } this.mapper.registerModule(JacksonUtil.bigIntToStrsimpleModule()); }
publicvoidserializeValue(Object object, Writer writer){ try { this.mapper.writeValue(writer, object); } catch (IOException var4) { thrownew TemplateProcessingException("An exception was raised while trying to serialize object to JavaScript using Jackson", var4); } } } }
// 属性绑定 // Bind the specified target Class using this binder's property sources. <T> BindResult<T> bind(String name, Class<T> target) <T> BindResult<T> bind(String name, Bindable<T> target, BindHandler handler) // Bind the specified target Class using this binder's property sources or create a new instance using the type of the Bindable if the result of the binding is null. <T> T bindOrCreate(String name, Class<T> target) <T> T bindOrCreate(String name, Bindable<T> target, BindHandler handler)
自动加载,没有时返回: null 自动加载,没有时自动加载一个: 102 批量获取,一个存在一个不存在时:{5dd53310-aec7-42a5-957e-f7492719c29d=102, 5dd53310-aec7-42a5-957e-f7492719c29d_1=103} print total cache: 5dd53310-aec7-42a5-957e-f7492719c29d_2==>11 5dd53310-aec7-42a5-957e-f7492719c29d_1==>103 5dd53310-aec7-42a5-957e-f7492719c29d==>102 total over
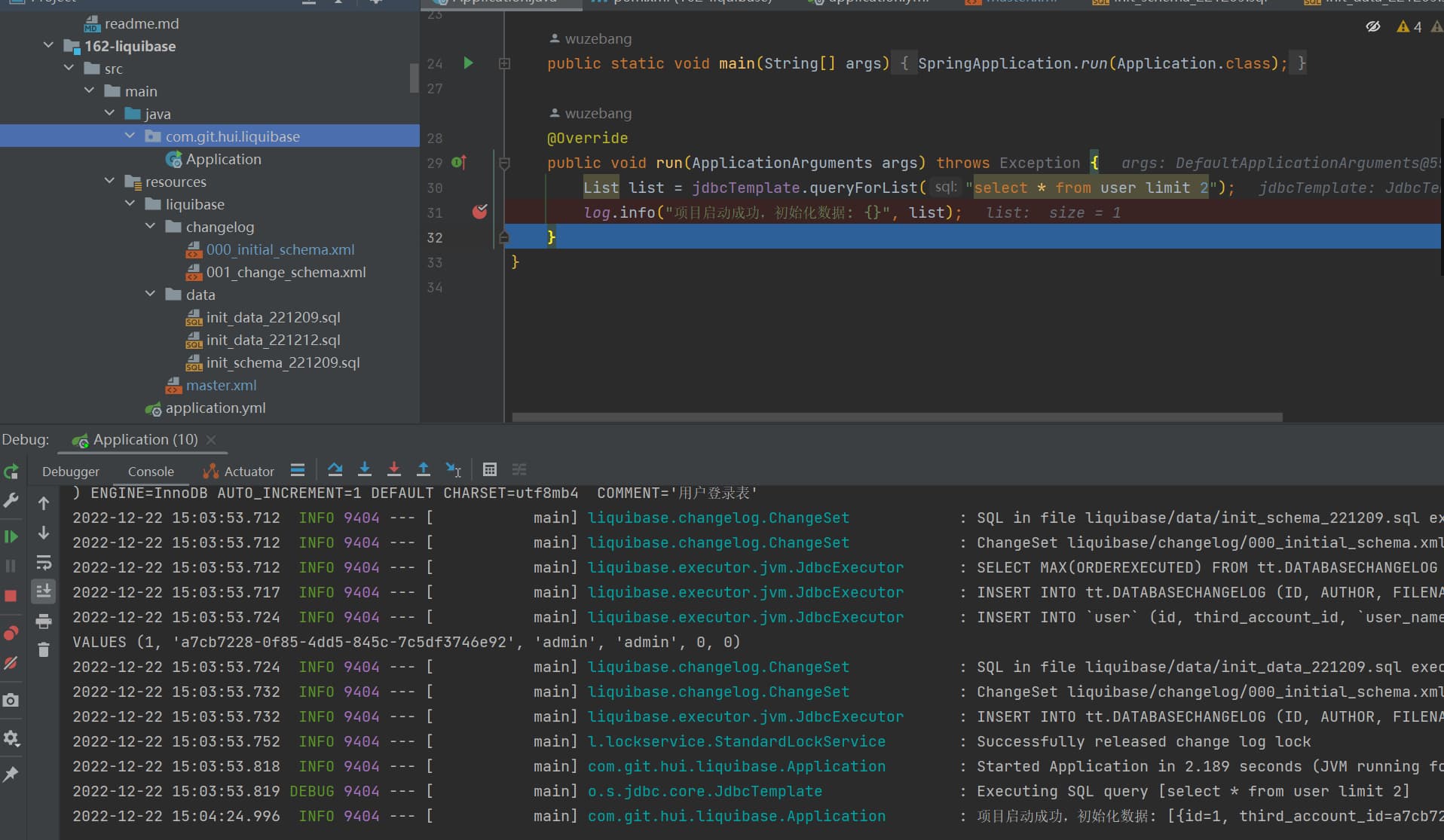
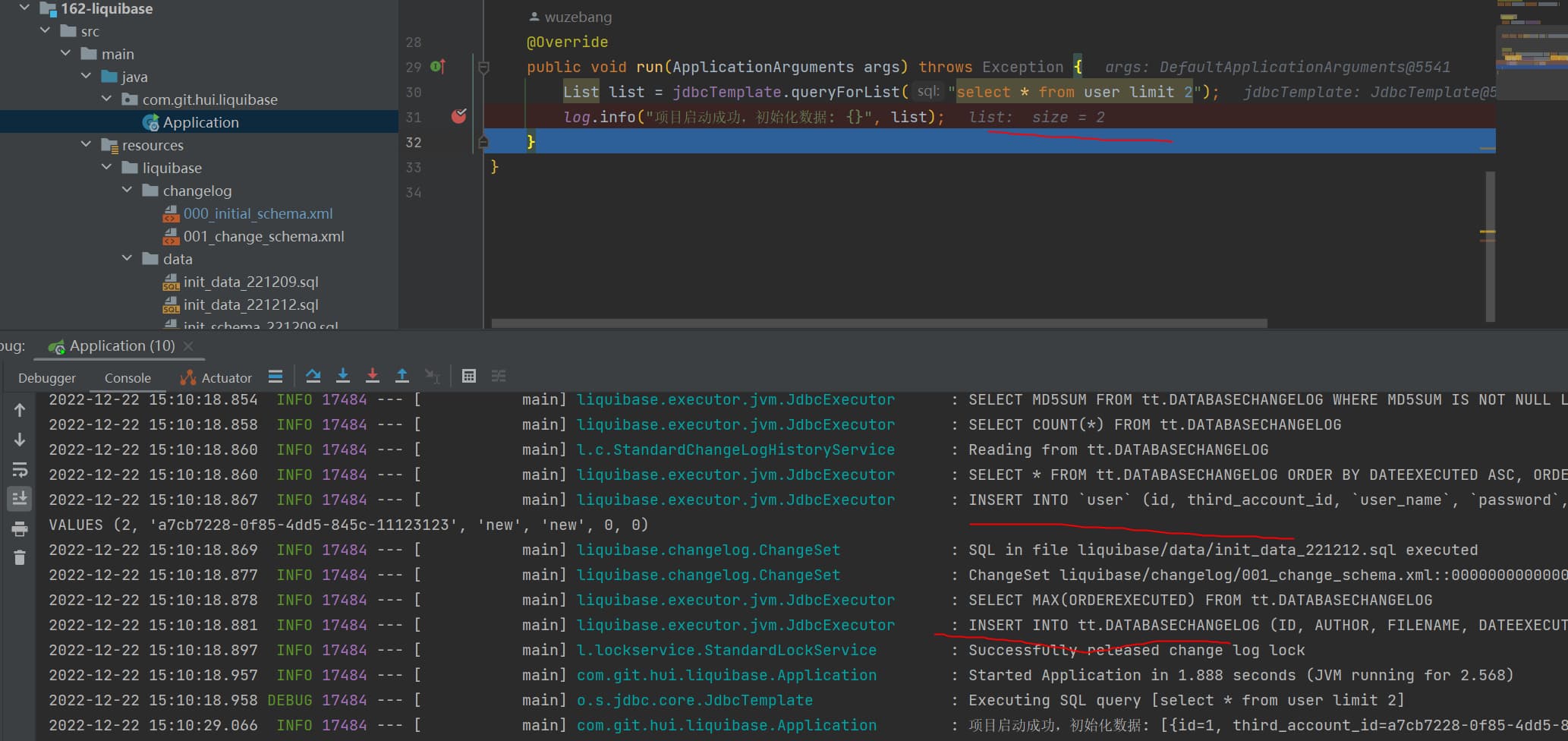
@Override publicvoidrun(ApplicationArguments args)throws Exception { List list = jdbcTemplate.queryForList("select * from user limit 2"); log.info("项目启动成功,初始化数据: {}", list); } }
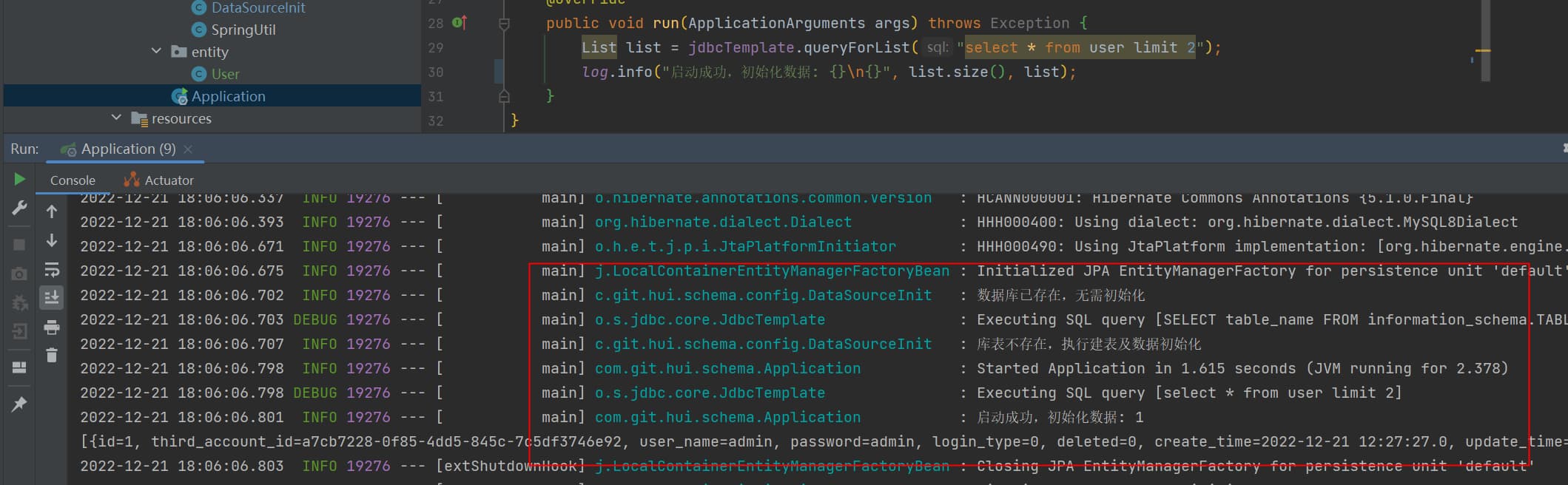
@Override publicvoidrun(ApplicationArguments args)throws Exception { List list = jdbcTemplate.queryForList("select * from user limit 2"); log.info("启动成功,初始化数据: {}\n{}", list.size(), list); } }